Programming NVIDIA GPUs with CUDAnative.jl¶
by: Tim Besard (GitHub: maleadt)
Talk: how does it work, what does it enable.
Workshop: how do you use CUDAnative.jl, realistically.
Follow along:
- slides: https://goo.gl/Rb1mo3
- single-page: https://goo.gl/pbT471
CUDA C replacement:
- low-level, kernel programming
- need to understand parallel & GPU programming
High-level wrappers: eg. GPUArrays.jl
Very usable, but restricted:
- wrt. Julia: language subset
- wrt. CUDA: limited functionality
Table of contents¶
- Requirements
- Installation
- Programming model
- Usage
- Performance & Optimization
- Debugging
1. Requirements¶
Operating system: Linux, macOS (unsupported)
Julia: 0.6, 0.7 (unsupported)
GPU: NVIDIA CUDA, sm >= 2.0
2. Installation¶
Dependencies: CUDAdrv.jl & LLVM.jl
LLVM.jl: requires Julia source build:
$ git clone https://github.com/JuliaLang/julia.git
$ cd julia
$ git checkout v0.6.0
$ make
$ ./juliaPkg.add("CUDAnative")
- Julia 0.6, LLVM 3.9.1
- Linux x64 (Arch Linux)
- NVIDIA driver 375.39
- CUDA 7.5
- NVIDIA GeForce GTX Titan
- Intel Core i7-3770k
3. Programming model¶
Single Program, Multiple Data
function execute(kernel, threads, args...)
global thread
for thread in 1:threads
kernel(args...)
end
end;
function kernel(a, b, c)
c[thread] = a[thread] + b[thread]
return
end;
a = [1,2,3]
b = [4,5,6]
c = similar(a)
execute(kernel, length(a), a, b, c)
a+b == c
Conceptually simple, but complex implementations:
- threads ∈ blocks ∈ grid
- storage behavior and performance
- thread communication & synchronization
Again, CUDAnative.jl does not obviate that complexity.
4. Usage¶
CUDAnative.jl takes care of:
- intrinsics
- compiler support
- language integration
Other CUDA operations: manual usage of eg. CUDAdrv.jl
- device management
- memory operations
- context handling
- ...
using CUDAdrv, CUDAnative
dev = CuDevice(0)
ctx = CuContext(dev)
# ...
destroy!(ctx)
CuContext(dev) do ctx
# ...
end
ctx = CuContext(dev);
GPU arrays¶
?CuArray
d_a = CuArray{Int}(2)
d_a[1] = 1
a = Array(d_a)
@cuda ... kernel(d_a)
Garbage collection¶
Mem.used() |> datasize
d_a = CuArray{Int}(10000000)
sizeof(d_a) |> datasize
Mem.used() |> datasize
finalize(d_a)
Mem.used() |> datasize
Avoid ERROR_OUT_OF_MEMORY: manual gc()
function kernel_vadd(a, b, c)
i = threadIdx().x
c[i] = a[i] + b[i]
return
end;
len = 42
a = randn(Float32, len)
b = randn(Float32, len);
d_a = CuArray(a)
d_b = CuArray(b)
d_c = similar(d_a);
@cuda (1,len) kernel_vadd(d_a, d_b, d_c) # asynchronous!
kernel_vadd<<<1,len>>>(d_a, d_b, d_c)
c = Array(d_c) # synchronizing
a+b ≈ c
Scale it up¶
len = 2048
a = randn(Float32, len)
b = randn(Float32, len);
d_a = CuArray(a)
d_b = CuArray(b)
d_c = similar(d_a);
@cuda (1,len) kernel_vadd(d_a, d_b, d_c)
attribute(dev, CUDAdrv.MAX_THREADS_PER_BLOCK)
attribute.(dev, (CUDAdrv.MAX_BLOCK_DIM_X,
CUDAdrv.MAX_BLOCK_DIM_Y,
CUDAdrv.MAX_BLOCK_DIM_Z))
function kernel_vadd(a, b, c)
i = (blockIdx().x-1) * blockDim().x + threadIdx().x
if i <= length(c)
c[i] = a[i] + b[i]
end
return
end;
threads = min(1024, len)
blocks = ceil(Int, len / threads)
@cuda (blocks,threads) kernel_vadd(d_a, d_b, d_c)
c = Array(d_c)
a+b ≈ c
?CUDAdrv.CuDim3
Reflection¶
CUDAnative defines: code_llvm, code_ptx, code_sass
Why? Custom toolchain
CUDAnative also defines:
@code_{lowered|typed|warntype}: defer to Base@code_llvm,@code_ptx,@code_sass: defer to CUDAnative
Why?
- decode
@cuda (...) kernel(...) - type conversions:
CuArray→CuDeviceArray
@code_llvm @cuda (1,len) kernel_vadd(d_a, d_b, d_c)
CUDAnative.@code_llvm @cuda (1,len) kernel_vadd(d_a, d_b, d_c)
@code_ptx kernel_vadd(d_a, d_b, d_c)
@code_sass kernel_vadd(d_a, d_b, d_c)
Advanced Less basic example¶
Reduce across columns.
const rows = 3
const cols = 4
a = collect(reshape(1:rows*cols, (rows, cols)))
cpu(+, a)
# naive GPU implementation
function gpu!(op::Function, data::CuDeviceMatrix)
col = blockIdx().x
row = threadIdx().x
offset = 1
while offset < row
a = data[row,col]
b = data[row - offset,col]
sync_threads()
data[row,col] = op(a,b)
sync_threads()
offset *= 2
end
return
end;
function gpu(op::Function, a::Matrix)
d_a = CuArray(a)
@cuda (size(a,2),size(a,1)) gpu!(op, d_a)
Array(d_a)
end;
cpu(+, a) ≈ gpu(+, a)
a = rand(Float32, 1000, 1000);
@benchmark cpu(+, a)
@benchmark gpu(+, a)
Benchmark the kernel time: CUDAdrv.@elapsed
function gpu_benchmark(op::Function, a::Matrix)
d_a = CuArray(a)
time = CUDAdrv.@elapsed begin
@cuda (size(a,2),size(a,1)) gpu!(op, d_a)
end
(time)u"s"
end;
gc()
minimum([gpu_benchmark(+,a) for _ in 1:1000]) |> u"ms"
Dwarfed by data transfer time.
Still, many possible kernel optimizations:
- work-efficiency
- shared memory cache
- memory load optimizations
- intra-warp communication without synchronization
Only going to discusse performance & optimization of Julia constructs!
5. Performance & Optimization¶
Launch performance¶
julia> using CUDAnative
julia> foo() = nothing
julia> Base.@elapsed @cuda (1,1) foo()
8.501839023 sjulia> Base.@elapsed @cuda (1,1) foo()
36.033 μsAs fast as statically compiled C!
julia> bar() = nothing
bar (generic function with 1 method)
julia> Base.@elapsed @cuda (1,1) bar()
105.534056 msInitial overhead: inferring & compiling infrastructure
Kernel performance¶
Rodinia benchmarks: CUDA C vs CUDAnative.jl
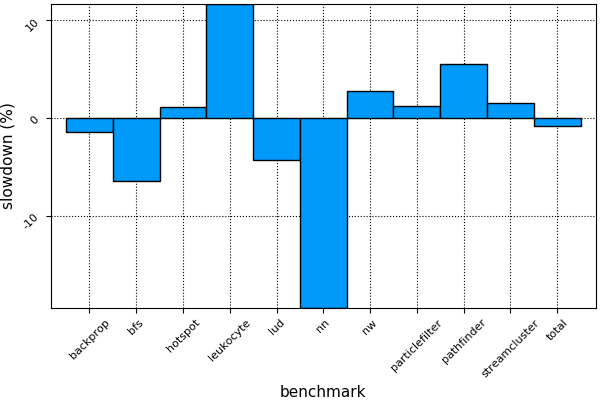
Performance is great! If you program carefully....
Passing non-bits types¶
function kernel(a)
a[threadIdx().x] = 0
return
end;
len = 1000
d_a = CuArray{Int}(len);
(@kernel_benchmark @cuda (1,len) kernel(d_a)) |> u"μs"
function kernel(ptr, len)
a = CuDeviceArray(len, ptr)
a[threadIdx().x] = 0
return
end;
(@kernel_benchmark @cuda (1,len) kernel(pointer(d_a), length(d_a))) |> u"μs"
Wide types¶
function dummy_kernel(a)
i = threadIdx().x
a[i] = CUDAnative.sqrt(a[i]*2.0)
return
end;
CUDAnative.code_ptx(DevNull, dummy_kernel, Tuple{CuDeviceArray{Float32,2}})
.visible .func julia_dummy_kernel(...)
{
.reg .f32 %f<3>;
.reg .f64 %fd<4>;
// a[i] * 2
ld.f32 %f1, [%rd4+-4];
cvt.f64.f32 %fd1, %f1;
add.f64 %fd2, %fd1, %fd1;
// a[i] = sqrt
sqrt.rn.f64 %fd3, %fd2;
cvt.rn.f32.f64 %f2, %fd3;
st.f32 [%rd4+-4], %f2;
ret;
}- extra register pressure → lower occupancy
- slower operations (up to 64x on consumer GPUs)
function dummy_kernel(a)
i = threadIdx().x
a[i] = CUDAnative.sqrt(a[i] * eltype(a)(2))
return
end;
CUDAnative.code_ptx(DevNull, dummy_kernel, Tuple{CuDeviceArray{Float32,2}})
.visible .func julia_dummy_kernel(...)
{
.reg .f32 %f<4>;
// a[i] * 2
ld.f32 %f1, [%rd4+-4];
add.f32 %f2, %f1, %f1;
/// a[i] = sqrt
sqrt.rn.f32 %f3, %f2;
st.f32 [%rd4+-4], %f3;
ret;
}Julia Base doesn't always care wrt. Int:
StepRanges promote small integers- use of literal numbers (eg.
1insize(::AbstractArray))
Profiling¶
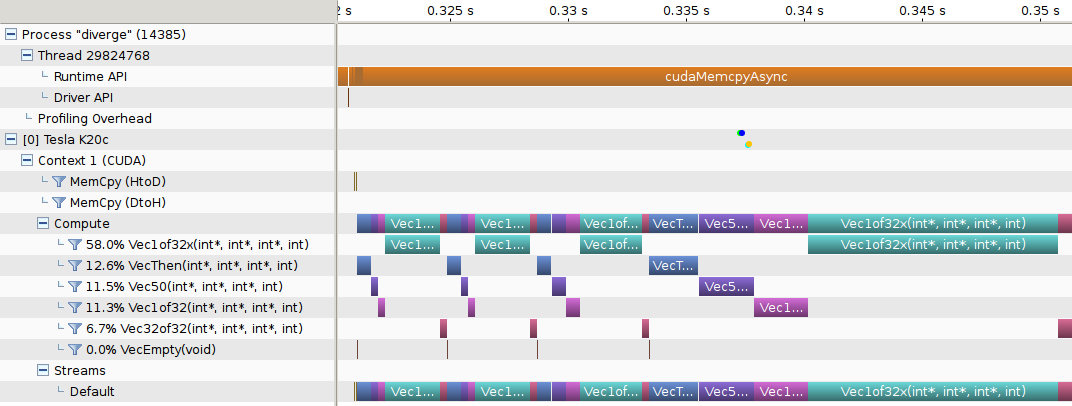
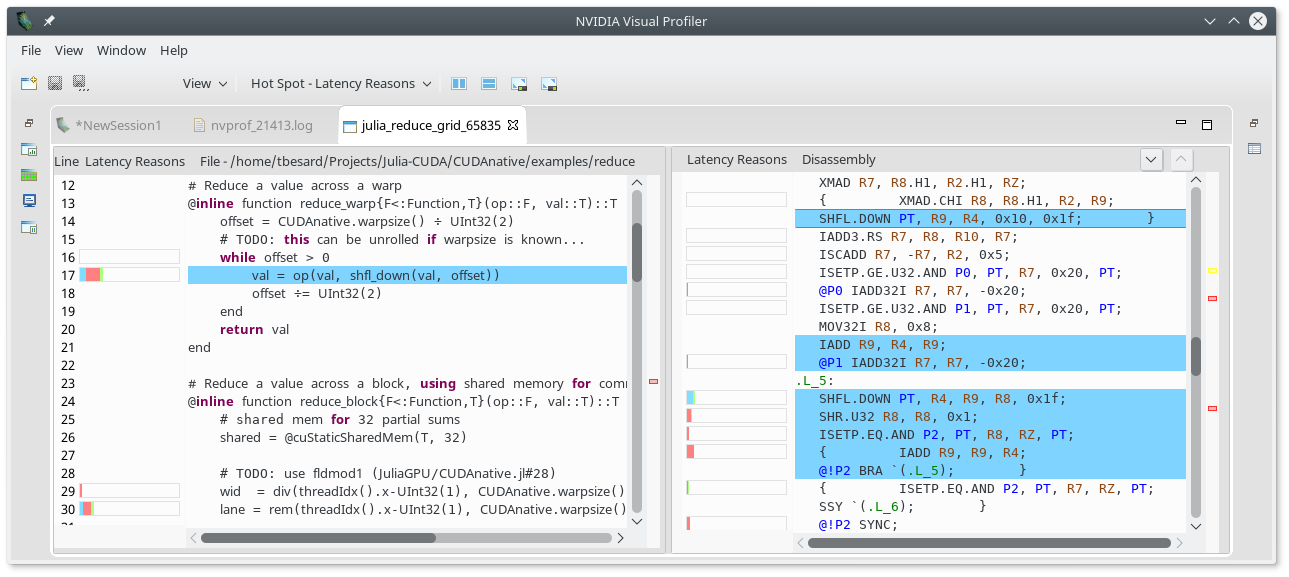
?CUDAdrv.@profile
?CUDAnative.@profile
6. Debugging¶
NVIDIA tools¶
$ cuda-memcheck julia examples/oob.jl
========= CUDA-MEMCHECK
========= Invalid __global__ write of size 4
========= at 0x000000b8 in examples/oob.jl:18:julia_memset_61129$ cuda-gdb --args julia examples/oob.jl
(cuda-gdb) set cuda break_on_launch application
(cuda-gdb) r[Switching focus to CUDA kernel 0, grid 1, block (0,0,0),
thread (0,0,0), device 0, sm 13, warp 0, lane 0]
julia_memset_61129<<<(1,1,1),(11,1,1)>>> () at examples/oob.jl:18
18 a[i] = val
(cuda-gdb) backtrace
#0 julia_memset_61129<<<(1,1,1),(11,1,1)>>> () at examples/oob.jl:18
(cuda-gdb) l
16 function memset(a, val)
17 i = (blockIdx().x-1) * blockDim().x + threadIdx().x
18 a[i] = val
19 return nothing
20 end(cuda-gdb) info locals
No locals.
(cuda-gdb) info args
No arguments.
(cuda-gdb) print val
No symbol "val" in current context.(cuda-gdb) layout split
┌──examples/oob.jl───────────────────────────────────────────────────┐
│16 function memset(a, val) │
│17 i = (blockIdx().x-1) * blockDim().x + threadIdx().x │
>│18 a[i] = val │
│19 return nothing │
│20 end │
┌────────────────────────────────────────────────────────────────────┐
│0x3df57e8 <julia_memset_61129+40> IADD R0, R0, 0x1 │
B+>│0x3df57f0 <julia_memset_61129+48> IADD.X R5, RZ, c[0x0][0x144] │
│0x3df57f8 <julia_memset_61129+56> IADD R6.CC, R0, -0x1 │
└────────────────────────────────────────────────────────────────────┘
multi-thre Thread 0x7ffff In: julia_memset_61129 Line: 18 PC: 0x3df57f0(cuda-gdb) next
(cuda-gdb) print $R5
$1 = 11Unsupported language features¶
kernel_returns() = 1;
@code_sass kernel_returns()
call_runtime() = Int[]
CUDAnative.@code_typed call_runtime()
CUDAnative.@code_llvm call_runtime()
function call_library(a)
i = threadIdx().x
a[i] = sin(a[i])
return
end
This kills the driver...
julia> synchronize()
ERROR: CUDA error: unspecified launch failure (code #719, ERROR_LAUNCH_FAILED)
julia> ctx = CuContext(dev)
ERROR: CUDA error: unspecified launch failure (code #719, ERROR_LAUNCH_FAILED)CUDAnative.code_llvm(DevNull, call_library, Tuple{CuDeviceMatrix{Float32}})
define void @julia_call_library_62847(...) {
...
%9 = tail call float
inttoptr (i64 139694085276592 to float (float)*)
(float %8)
...
}function call_library(a)
i = threadIdx().x
a[i] = CUDAnative.sin(a[i])
return
end
CUDAnative.code_llvm(DevNull, call_library, Tuple{CuDeviceMatrix{Float32}})
define void @julia_call_library_62847(...) {
...
%9 = tail call float @__nv_sinf(float %8), !dbg !19
...
}Output modes¶
DEBUG=1 julia --compilecache=no examples/vadd.jl
Checking validity of CUDA/driver/current/libcuda.so
Checking validity of bundled library at julia/usr/lib/libLLVM-3.9.1.so
(Re)compiling kernel kernel_vadd(...) for device capability 3.5.0
intrinsics/indexing.jl:18: marked this readnone call a tail call candidate
intrinsics/indexing.jl:44: marked this readnone call a tail call candidate
intrinsics/indexing.jl:10: marked this readnone call a tail call candidate
JIT info log:
ptxas info : 0 bytes gmem
ptxas info : Compiling entry function 'kernel_vadd' for 'sm_35'
ptxas info : Function properties for kernel_vadd
ptxas . 0 bytes stack frame,
ptxas . 0 bytes spill stores,
ptxas . 0 bytes spill loads
ptxas info : Used 14 registers, 344 bytes cmem[0]TRACE=1 julia --compilecache=no examples/vadd.jl
cuDriverGetVersion(version_ref=Base.RefValue{Int32}(...)) = 0
cuInit(flags=0) = 0
LLVMInstallFatalErrorHandler(Handler=Ptr{Void} 0x...) = nothing
LLVMGetGlobalContext() = Ptr{LLVM.API.LLVMOpaqueContext} 0x...
cuDriverGetVersion(version_ref=Base.RefValue{Int32}(...)) = 0
cuDeviceGet(handle_ref=Base.RefValue{Int32}(...), ordinal=0) = 0
cuCtxCreate_v2(handle_ref=Base.RefValue{Ptr{Void}}(...),
flags=SCHED_AUTO, dev=CUDAdrv.CuDevice(0, 0)) = 0
...
Finalizing CuContext at 0x...
cuCtxDestroy_v2(ctx=CUDAdrv.CuContext(Ptr{Void} 0x..., true, true)) = 0
Invalidating CuContext at 0x...
Skipping finalizer for CuArray at 0x... because context is no longer valid
Skipping finalizer for CuArray at 0x... because context is no longer valid
Skipping finalizer for CuArray at 0x... because context is no longer valid
Skipping finalizer for CuModule at 0x... because context is no longer validThat's it!¶
Talk on CUDAnative.jl (Wednesday):
- GPU parallelism & optimization
- CUDAnative.jl inner workings
Lightning talk on LLMV.jl (Thursday)